做一个 Google 的网页代理

年末了,我不久就要回到墙内见见好久不见的亲朋好友,感受祖国的怀抱。不过祖国的怀抱不全是温暖的,比如,如果我想上一下 Google ,那就得花上原来十几倍的功夫。而经常用 Google 的人都知道,这东西不是随随便便的百度搜狗 360 这种渣渣可以替代的。
翻墙软件的麻烦
我有上 Google 的需求,但是这个需求要怎样才能满足呢?当然是翻墙了。有自由门、无界这种开发者比较敏感而且正邪未知的翻墙软件 / 服务,也有赛风、 Tor 、 XX-Net 这种自由而且开源的翻墙软件 / 服务,当然也少不了备受好评、自由开源,但是需要自己架设服务器的 Shadowsocks 。
我是比较偏向中间三种以及最后一个的,不过它们都有一个很大的缺点,那就是它们都需要你在需要翻墙的设备上装一个客户端。这情有可原,因为能存活至今的翻墙软件必须都得用特殊的网络连接方式,不像 VPN 一样许多操作系统都内置支持,而 VPN 早已不能被用来翻墙。
对客户端的需求带来了两个很严重的问题:第一个是平台支持,比如 Shadowsocks 有 Linux, Mac OS X 以及 Microsoft Windows 的客户端,也有 Android 的客户端,但是它没有 iOS 和 Windows Phone 的客户端。这样在 iOS 和 Windows Phone 的设备上使用 Shadowsocks 翻墙就成为了几乎不可能的事情。 iOS 有个 Surge ,不过它并不是被设计成用来翻墙的, Shadowsocks 只是个附带功能,而它本身是个专业工具,要花上 $9.99 才能够使用,最致命的是它上周已经下架了。
第二个问题是机动性不足。还是拿 Shadowsocks 来举例,我需要在一台电脑下载并配置好这个客户端,配置好了以后还得改浏览器代理设置,然后才能够享受自由互联网。在自己的设备上这样做也就稍微折腾一下,不成问题,但是如果你在使用别人的设备呢?先排除上一段已经讲过的平台兼容性问题,在别人的设备上装软件总是不太好的吧。如果你使用的是公共设备,比如图书馆里的电脑,那不但麻烦(得重新折腾),而且图书馆一般不会给你管理员权限,你还不一定装的上。
反向代理的缺点
有什么办法呢?我没有办法,要翻墙还是不得不需要一个客户端。但是,有一种方式,可以让你无需翻墙就可以访问原本需要翻墙才能访问的服务。这种方式叫做反向代理。
反向代理的原理就是你请求反向代理服务器,反向代理服务器根据它的配置将你的请求转发给目标网站的服务器,在收到目标网站的服务器的回复后,再把那个回应转发给你。总之就是绕了一个圈子,不过不管怎么样,这样做确实可以免翻墙访问原本被墙的网站。
因为 Google 是我最需要免翻墙访问的网站 / 服务,所以我很快用 Nginx 搭了一个 Google 的反向代理,不过效果差强人意。
一个反向代理只能代理一个网站的内容。而许多网站都需要在网页中加载外部资源(比如图片、样式),这些资源有些经常不是来自网页所属于的那个域名的,要访问资源必须访问另一个域名,而那样的域名通常也是被封的。再搭一个反向代理?不行,因为网页的 HTML 中就写着它需要那个域名里的资源,浏览器不知道你在用反向代理,不会把它的链接转向你的另一个反向代理。
更蛋疼的是链接。会 HTML 的人都知道,链接有两种:相对链接和绝对链接,相对链接会链接到相对于当前网页的一个地方,比如在 https://example.com/posts/ 中,一条内容为 a 的链接会将你链接到 https://example.com/posts/a 中去。而绝对链接以 / 开头,代表这个域名的根目录,在这个例子中就是 https://example.com/ ,一条内容为 /a 的链接会无视当前页面的路径,直接将你定向到这个域名的根目录中的 https://example.com/a 上去。
如果你将你的反向代理挂在 https://example.com/reverse-proxy/ 里面,将 https://example.com/ 中的其他路径做别的用途。反向代理指向 https://test.org/ ,你得到的 HTML 中有一个链接 /a 。在原来的地址 https://test.org/ 中它会指向 https://test.org/a ,这是正确的。可是如果你通过反向代理 https://example.com/reverse-proxy/ 访问的话,链接就会指向 https://example.com/a ,这可不对,跑到我不用来做反向代理的地方去了,它应该指向 https://example.com/reverse-proxy/a 才对的。可是这有什么办法呢?让服务器替换 HTML 中的内容吗?但 HTML 很复杂,里面还会有 JavaScript 什么的就更复杂了,一个个替换起来是件很复杂的事情。
以上两段就是我在决定开始开发 Curly Turtle 前所遇到的问题。
Curly Turtle 的特性
既然替换 HTML 中的链接行不通,为什么不干脆把原来的 HTML 扔掉,重新组建成一个包含信息的网页呢?
我的设计草图是这样的:用户请求服务器,服务器知道了用户需要什么之后再去请求 Google 的服务器, Google 会给它一堆 HTML ,这个软件需要把搜索结果从 HTML 中提取出来,然后使用自己的网页模板,将结果返回给用户。
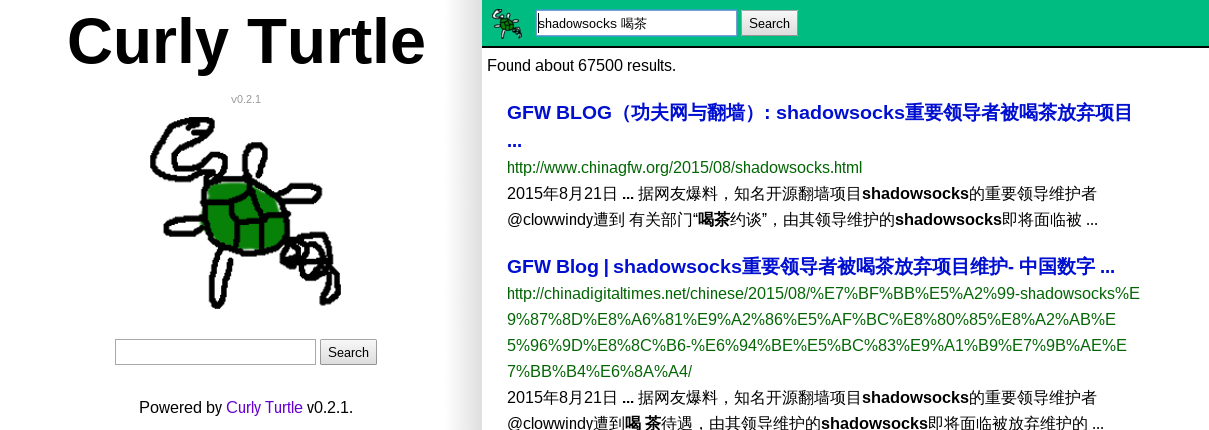
然后我就新开了一个坑,叫 Curly Turtle ,一个解析 Google 给出的 HTML 再重新组建网页的反向代理服务器程序。不对,这样不能叫反向代理了,只能叫网页代理,不过叫网页代理也不太贴切,因为它只能访问 Google 一项服务。啊,不管了,我们就把它叫做网页代理。题图就是它在客户端上给出的网页。
如果你想让你的代理放在一个子目录中,只要告诉 Curly Turtle ,它就会把返回的 HTML 中的所有站内绝对链接变成带有这个子目录的。比如你想把代理放在 https://example.com/reverse-proxy/ 里,网页上的绝对链接全会在前面被加上 /reverse-proxy 。
因为我觉得访问自由互联网是每个人的自由 ,所以为了争取这项自由所使用的软件也应当是自由的。 Curly Turtle 采用 GPL v3 授权开放源代码(嘛,虽然应该写的很垃圾)放在了 GitHub 上,对于如何使用它的说明也在那里,链接在这儿。
不得已的妥协
有人可能会问我,为什么一定需要一个子目录呢?
因为我不想让别人知道我的服务器上有 Curly Turtle 在运行。 我不是在做一个镜像站 ,不是因为我小气,不愿意给大家分享,当然不是这样的,这有悖自由的原则。但是我不敢啊,大家还记得谷粉搜搜吗?这是一个 Google 的镜像站,原理应该跟 Curly Turtle 类似,这个网站为所有人开放,提供 Google 的搜索结果。为了能不被和谐,还主动自我审查不让人搜敏感词(我想作者也不愿意这样做,但这没办法是不?)。但即使这样,他的维护者还是不得不关闭了谷粉搜搜。不难猜想,他是受到了有关部门的威胁。
现在你寻找谷粉搜搜你还能找到一个域名为 gufensoso.com 的网站,但是请相信我,我在两年前用谷粉搜搜的时候它的域名是 gfsoso.com 。而后者已经如上一段所说,关闭了。作者说自己以后不能再制作类似的网站。所以我很难说这个新的谷粉搜搜究竟靠不靠谱……
类似谷粉搜搜这样的网站有好几个,不过只要维护者在墙内的,现在几乎都已经被有关部门打压完了。由此可见,做一个镜像站不是长久之计,甚至还有可能面临被查水表的危险。所以干脆就做成像 Shadowsocks 这样的,自己在 VPS 上搭,自己使用。
为了不让别人知道我的服务器上有一个可以提供免翻墙 Google 搜索的服务在运行,把东西放在根目录是肯定不行的。我只能让 Curly Turtle 对知道我设定的子目录的人作出回应,否则就返回 404 。为了安全最好还把这个子目录设的长一点,比如如果把代理放在 https://example.com/OUv-KeMvBxRbYg02H 里,让别人发现就很难了。
如果你觉得你想要用 Curly Turtle 搭一个公共的网页代理,那当然是极好的。但是请原谅我打击你的积极性,如果你在中国大陆,为了你 VPS 能使用得更长久一些,为了你的人身安全,别这么做。当然你要是最后真分享出来了还流传很广还没被查水表,把我的脸打的啪啪响,那我也心甘情愿被打啊。
最后的顾虑
不过即使我没有提供服务,只是给出了软件,我还是很心虚的。因为 Shadowsocks 也没有提供服务,而它的主要作者已经被查水表了。
我这是在做死……😭
最后再说一遍,代码以及使用说明在这里: https://github.com/FiveYellowMice/curly-turtle